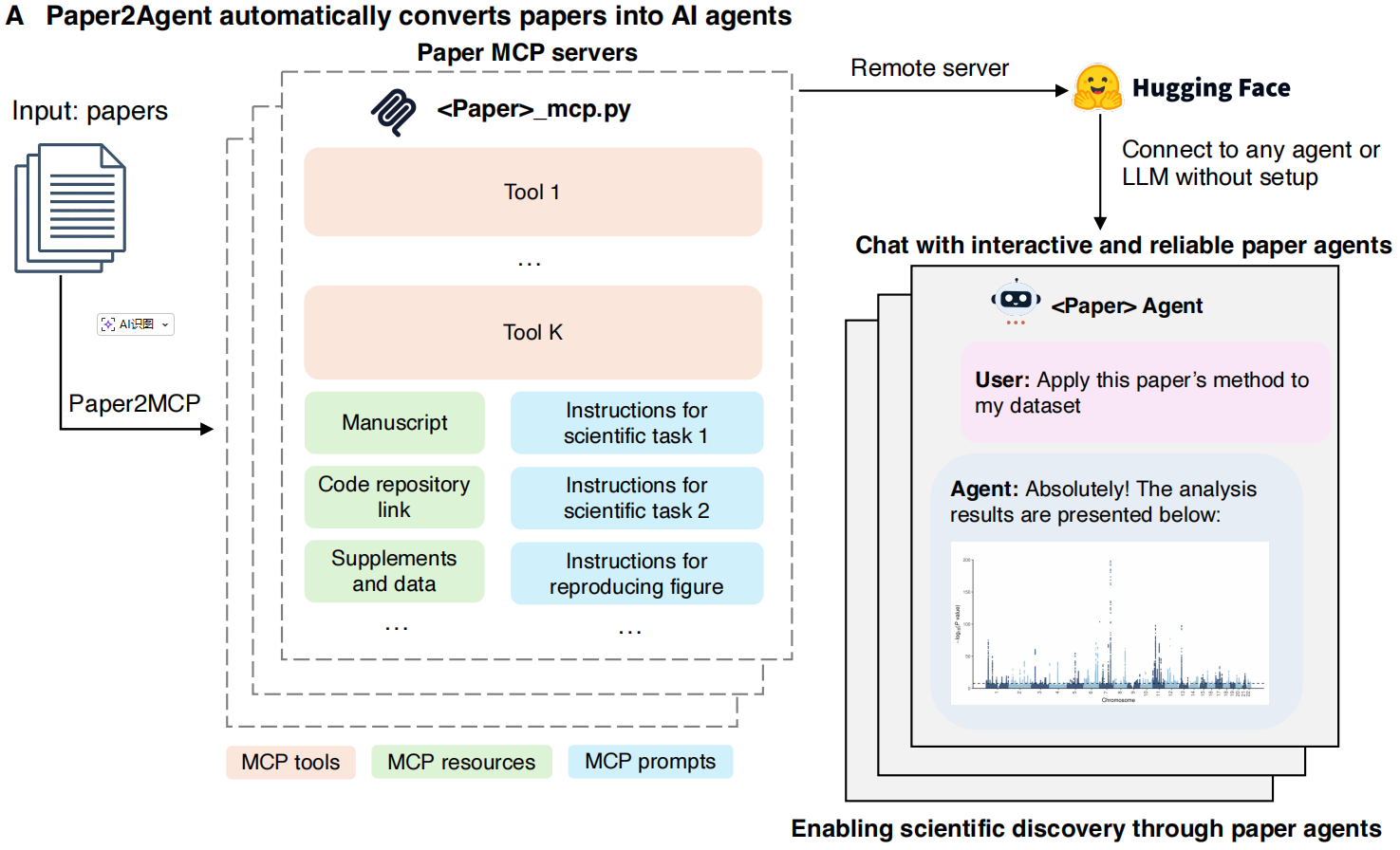
为此,我们在开源框架Paper2Agent的基础上开发了一个交互可视化的版本。跳过了所有繁琐步骤,自动将论文转化为AI智能体。在正确的数据和设置下运行真实代码,直接给出结果。
- 无需用户进行手动调试或复杂配置,系统可视化交互响应操作。
- 不仅能在预设的标准化环境中精准运行论文原始代码,高度复现原研究结果,还能灵活处理全新的个性化查询。
在AlphaGenome、TISSUE、Scanpy 等多个重负载案例中经过测试,均实现了与原论文结果的高度一致,充分验证了其在复杂场景下的稳定实用性。
核心架构
- 通过MCP 协议,将论文中的数据集、代码路径、多步工作流等核心资源,统一编码为可寻址、可组合、可查询的标准化资源,让原本分散的科研方法形成一个清晰、规整的调用接口。
- 打包整合论文所需的可执行工具函数、静态资源和步骤化Prompt,使静态的科研文档转变为可演示、可应用、可适配的动态系统,将成果复现过程本身封装成稳定可靠的调用接口。
")
实现流程
- 环境搭建:以确定论文代码库为基础,由环境代理搭建可复现的依赖环境,并严格锁定依赖版本,从源头避免环境差异导致的运行故障。
- 工具抽取:抽取代理将论文脚本拆解为单一职责的独立工具,确保每个工具功能明确、边界清晰,可被单独调用且互不干扰。
- 测试优化:测试代理持续运行打磨工具,直至工具行为符合预期。
- 封装部署:通过验证的工具会被封装为Python MCP 服务并部署,方便科研人员协作共享,大幅降低成果复用与传播的成本。
整个构建过程中,每个工具均保留回溯至原始源代码的线索,确保行为可追踪、可追溯;同时优先通过已审校的工具完成调用,减少自由生成代码带来的随机性,进一步保障了系统运行的稳定性与结果的可靠性。
")
重塑新范式
使用说明
初始配置:首次使用需先完成模型配置,点击页面右上角的"模型配置"进入模型配置中心,选择"主模型配置"选项,根据需求设置LLM参数,设置完成后点击"保存当前配置"确认,后续点击"配置验证器" 选项,补充设置验证LLM参数,完成模型配置。
")
文件选择:选择输入文件的类型,支持PDF、DOCX、 DOC、TXT格式的文档,以及Python脚本、Jupyter Notebook 格式的脚本。按需选择选择对应文件类型,点击"选择文件"导入已选定类型的目标文件。若需快速掌握文件核心内容,可选择点击"文章理解",AI会自动精读文件并生成结构化摘要,摘要结果会实时显示在中间的"AI论文理解"展示区域。
")
输出设置:可自定义设置输出文件夹路径,精准指定文件保存位置,自定义输入项目名称,便于后续识别和管理生成的文件,若需恢复默认存储规则,点击「重置默认输出路径」即可还原系统预设配置。
")
开始转换:点击"开始转换",启动文件处理流程,右侧面板将实时显示转换处理阶段,无需额外操作,等待处理完成后,系统将自动生成完整的项目文件包在指定目录。输出结果包含两个文件夹,一个包含代码运行文件,一个包含项目运行文件,项目运行文件输出结构包含一下内容:
├─ src/ │ ├─ tools.py (提取的工具函数) │ ├─ mcp_server.py (MCP服务器) │ ├─ web_api.py (Web API接口) │ └─ mock_system.py (依赖模拟系统) ├─ templates/ │ └─ index.html (Web界面) ├─ requirements.txt (Python依赖) ├─ start.bat (一键启动脚本) ├─ start_mcp.bat (单独启动MCP) └─ start_web.bat (单独启动Web)
")
下载信息
文章标题:Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents
文章链接:https://arxiv.org/abs/2509.06917
百度网盘链接: https://pan.baidu.com/s/18tfMBAoL-TTAkASdmcxBjQ?pwd=yqy9 提取码: yqy9